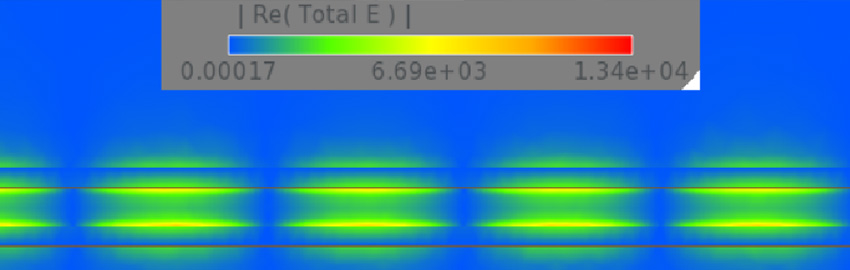
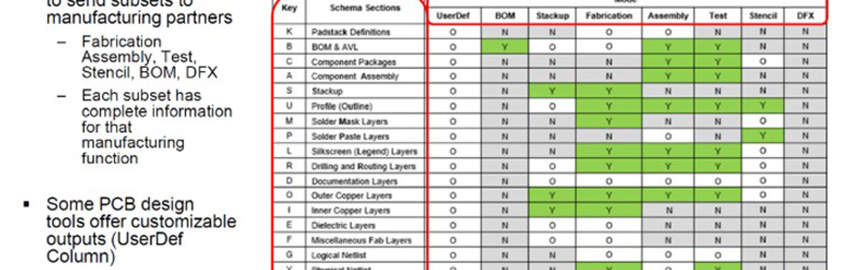
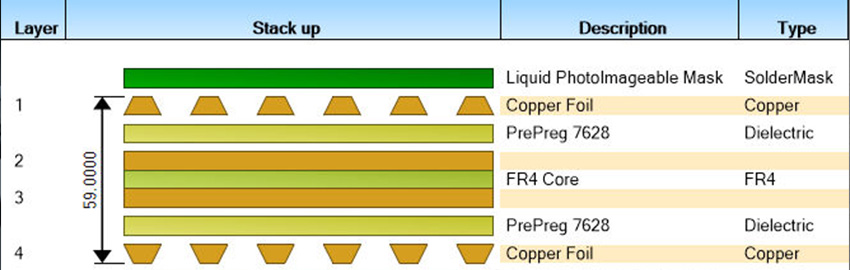
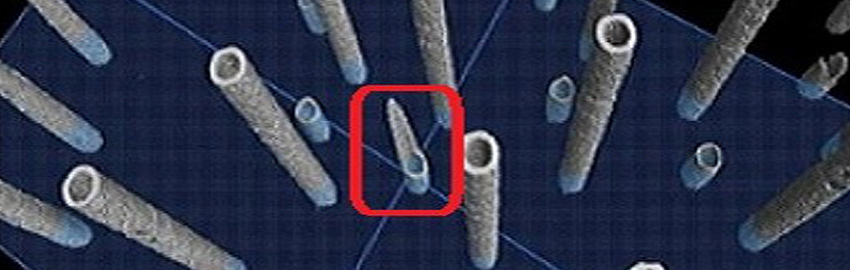
High-performance computing has moved out of its niche to become a mainstream requirement and continues to rely on human skills to deliver its optimum potential.
High-performance computing has moved out of its niche to become a mainstream requirement and continues to rely on human skills to deliver its optimum potential.
Historically, supercomputing has been a niche discipline, the preserve of rare and almost mythical machines embodying esoteric design principles. Only a tiny number of organizations, such as national laboratories, top-tier businesses and elite universities, had workloads that justified using them. Also, there were only a few engineers and scientists in the world capable of running them.
Now, thanks to several generations of technology scaling, compute performance is more readily and cheaply available at any level, from tiny, embedded microcontrollers to desktop machines, rack servers and hyperscale cabinets. Together with innovative concepts like Beowulf clusters, which build supercomputers from general-purpose off-the-shelf computers at a fraction of the cost, these have created a democratizing effect that has helped set the scene for practicable and affordable high-performance computing (HPC) as we know it today. The PCB industry has played its part, providing substrates that not only support high signal speeds but also critically address the thermal issues intrinsic to HPC.
Driving this ingenuity, of course, are the market dynamics affecting today’s businesses and research institutions. Companies can no longer rely on incremental product improvements or greater supply chain efficiency to compete for market share, and researchers seeking progress in increasingly complex fields need to deliver results quickly to meet funding obligations. The key to success in these times is computational. As more computing means greater advantage, more organizations need HPC to handle workloads such as retail demand forecasting, biotech simulations, financial risk modeling and digital twinning. While they may not be “supercomputer workloads” in the old sense, these are the challenges HPC was built for.
Where should HPC be implemented, and how? There are several options, and all have their advantages and drawbacks. On‑premises HPC can suit organizations with steady, intensive, tightly coupled workloads that justify owning specialized hardware and the staff to run it. The Beowulf clusters I mentioned earlier, which rely on tuning instinct and tacit knowledge within the management team, are less common now than vendor-supported hardware that offers advantages such as predictability and lifecycle management.
The alternative is the cloud. Running HPC workloads here can offer greater flexibility and faster access to new hardware options, providing a pay-as-you-go model that can help companies reduce capital expenditure. Some workloads can be more expensive to perform in the cloud, while hazards can include latency and performance variability. Also, opportunities for users to fine-tune the hardware can be limited.
The importance of fine-tuning highlights the value of human know-how in running an enterprise HPC system. While managing ordinary enterprise IT prioritizes standardization, repeatability and risk minimization, running an on-premises HPC cluster emphasizes optimization and maximizing hardware performance. Key concerns are density, requiring concentrated processing power closely coupled with storage, and latency across memory interfaces and in data exchanges. Typical ways to address latency include high-bandwidth interfaces such as InfiniBand and kernel-bypass techniques that enable direct access to data storage and hardware resources. Techniques like these can bring latency down into the single-digit microsecond range and are usually specific to HPC, quite unlike the standardization and generalization sought by enterprise IT teams.
Managing on-premises HPC effectively requires an intimate grasp of the organization’s computational workloads, as well as the technicalities of building and running the machines. With the option to move HPC to the cloud, organizations need to retain this human-contained value that truly understands the minute details of workloads and their interactions with hardware.

Figure 1. High-performance computing has evolved from specialized supercomputers to widely accessible clusters and cloud platforms, enabling organizations to tackle increasingly complex computational workloads while still relying on human expertise for optimization and management.
Into this discussion comes the concept of infrastructure as code (IaC), which automates the provisioning of compute resources. IaC permits repeatable builds and faster adoption of new hardware, with provision for version control. It also eases scaling, makes workloads portable, and supports system rebuilds, thereby aiding disaster recovery. While IaC can bring these qualities to on-premises HPC, it’s an essential tool for companies seeking to run part or all their HPC in the cloud. It becomes possible to build, run and tear down a cluster in hours on rented hardware that can then be reassigned to another subscriber.
We could perceive IaC as yet another instance in which automation, powered by software-defined-everything, is forcing humans out of the equation. But it’s changing, rather than replacing, the role of the enterprise HPC team. Instead of tending to the tangible equipment in the computer room, in-house teams are focusing on high-level activities, working with the company’s HPC users to define the compute environment that automated tools must then reproduce. This makes it possible for the HPC engine to be hosted on-premises, in the cloud, in a hybrid of the two, or even on multiple clouds. The team’s expertise makes this possible by applying their combined understanding of workloads and infrastructure to optimize profiles, ensure the cluster behaves as desired, and manage cost/performance trade-offs.
The story of HPC is intriguing and, in many ways, closely parallels the general arc of progress in the high-tech economy. It’s become a defining requirement for organizations, both large and small, and a critical capability for competing. Enabled by the commoditization of powerful compute and high-density memory, it has democratized supercomputing and is transforming the business landscape as well as the hardware sitting in on-premises server rooms. Off-premises, the big computing companies offer HPC services that leverage automated tools, allowing customers to configure their own HPC clusters to handle specific workloads. Either way, ensuring that users' needs are met effectively and as efficiently as possible remains contingent on human skills and expertise.
Alun Morgan is technology ambassador at Ventec International Group (venteclaminates.com); This email address is being protected from spambots. You need JavaScript enabled to view it.. His column runs monthly.